О восприятии звука и музыки.
30 марта 2011

Частотный спектр, несущий информацию в человеческой речи: от 500 Hz до 2 kHz.
Низкие частоты — басы и гласные. Высокие частоты — согласные. Лучшее сжатие речи достигается с использованием параметрических кодеров (LPC, CELP, и пр.), пытающихся представить речь как набор параметров некоторой речевой модели. Кодеки общего назначения (MPEG и др.), как правило, дают худшее сжатие.
Простые методы сжатия
Традиционные методы сжатия без потерь (Huffman, LZW, итд.) обычно плохо применимы для сжатия аудио информации (по тем же причинам что и при сжатии визуальной информации).
Ниже перечислены некоторые методы сжатия с потерями:
* Сжатие тишины(пауз) - определяет периоды "тишины", работает аналогично run-length кодированию.
* ADPCM - Adaptive Differential Pulse Code Modulation (в русскоязычной литературе применяется термин адаптивная дельта-импульсно-кодовая модуляция (АДИКМ).
Например, стандарт CCITT G.721 -- от 16 до 32 Kbits/sec:
Кодирование разницы между двумя или более последовательными отсчетами; затем разница квантуется --> при квантовании часть информации теряется. Квантование адаптивно (меняет параметры в зависимости от сигнала), в результате меньшее количество бит необходимо для достижения лучшего SNR. Необходимо предсказывать как звук изменится --> сложно
* Apple разработал собстенную систему названную ACE/MACE. Сжатие с потерями, пытается предсказать, каково будет значение следующего отсчета. Сжатие порядка 2:1.
* Linear Predictive Coding (LPC) - пытается описать сигнал с помощью "речевой модели" и передает параметры модели --> звучит как компьютерно синтезированная речь, 2.4 kbits/sec.
* Code Excited Linear Predictor (CELP) - тоже самое что и LPC, однако дополнительно передает ошибку квантования (используя предопределенный набор "кодовых слов") --> телефонное качество при 4.8 kbits/sec.
Методы сжатия, основанные на психоакустике
Представители: MPEG layers 2, MPEG layer 3 (MP3), AAC (Advanced audio coding), TwinVQ, Ogg Vorbis, и др.
Алгоритм кодека использующего психоакустику обычно состоит из следующих шагов:
* Обсчет психоакустической модели (маскирования).
* Разделение сигнала на частотные подполосы (FFT, DCT/MDCT, FilterBanks, и т.д.).
* Квантование сигнала в подполосах в соответствии с результатами психоакустической модели. Возможно использование одного квантового уровня. сразу для нескольких входных значений (векторное квантование - Vector Quantization) - TwinVQ.
Некоторые факты о восприятии звука
* Частотный спектр воспринимаемый человеком (примерно) от 20 Hz до 20 kHz, наибольшая чувствительность в диапазоне от 2 до 4 KHz.
* Динамический диапазон (от самых тихих воспринимаемых звуков до самых громких) около 96 dB (более чем 1 к 30000 по линейной шкале).
* Общеизвестно, что человек в состоянии различить изменение частоты на 0.3% на частоте порядка 1kHz.
* Если два сигнала различаются менее чем на 1дб по амплитуде - они трудноразличимы. Разрешение по амплитуде зависит от частоты и наибольшая чувствительность наблюдается в диапазоне от 2 до 4 KHz.
* Пространственное разрешение (способность к локализации источника звука) - до 1 градуса.
* Звуки различной частоты распространяются в воздухе с разной скоростью. В результате высокочастотная часть спектра от источника находящегося на удалении от слушателя несколько запаздывает.
* Человек не в состоянии заметить внезапное исчезновение высоких частот, если оно не превышает порядка 2ms.
* Некоторые исследования показывают, что человек в состоянии ощущать частоты выше 20kHz. С возрастом частотный диапазон сужается.
Речь
* Частотный спектр, несущий информацию в человеческой речи: от 500 Hz до 2 kHz
Низкие частоты - басы и гласные
Высокие частоты - согласные
* Лучшее сжатие речи достигается с использованием параметрических кодеров (LPC, CELP, и пр.), пытающихся представить речь как набор параметров некоторой речевой модели. Кодеки общего назначения (MPEG и др.), как правило, дают худшее сжатие.
Устройство уха
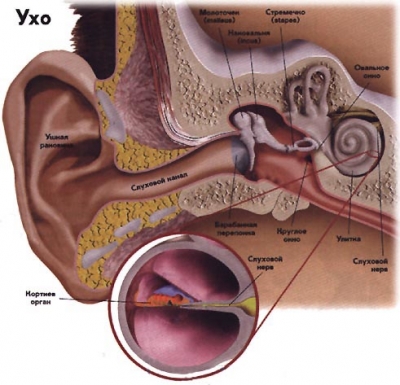
В общем случае ухо - нелинейная система и не может быть точно описано с помощью только линейных элементов (таких как фильтры и линии задержки). Как побочный результат нелинейности может проявляться, например, следующий эффект: при подаче двух тонов с частотой 1000 и 1200Hz может также быть слышен третий тон с частотой 800Hz. Однако в интересующем нас диапазоне амплитуд нелинейность достаточно слаба и ей обычно пренебрегают.
Строение
Ухо состоит из трех частей: ушной раковины (также называемой внешним ухом), среднего уха и внутреннего уха - улитки. Проходя через различные части уха звук претерпевает изменения.
* Одна из функций внешнего уха (ушной раковины) - улучшение локализации источника звука в пространстве. Благодаря ее несимметричной форме АЧХ сигналов приходящих из разных точек пространства изменяется по разному. Ушная раковина может влиять лишь на сигналы с длинной волны, сопоставимой с размерами уха (>3kHz). Внешний ушной канал резонирует на частоте около 2kHz , что дает повышенную чувствительность в данном диапазоне.
* Среднее ухо выполняет роль гидравлического усилителя. Так как в улитке находится жидкость а снаружи - воздух, то необходимо согласование сопротивления среды. Среднее ухо также защищает от низкочастотных звуков чрезмерной амплитуды.
* Внутреннее ухо - улитка. В развернутом виде будет представлять из себя трубочку, с постепенно уменьшающимся к одному из концов диаметром. Улитка выполняет роль частотного анализатора. Внутри улитки находятся до 4000 нервных окончаний. Различные области улитки входят в резонанс при подаче сигнала определенной частоты.
Восприятие в зависимости от частоты
* Так как нейрон может возбуждаться не чаще чем 500 раз в секунду, то для получения информации о более высоких частотах слуховой аппарат человека прибегает к некоторым "ухищрениям":
На частотах до 500 Hz --> колебания непосредственно переходят в нервные импульсы.
Примерно до 1.5кГц проблема решается подключением одновременно до 3 нейронов к одному нервному окончанию. Нейроны в данном случае возбуждаются последовательно, один за другим и, соответственно, помогают улучшить частотное разрешение в 3 раза.
На более высоких частотах регистрируется лишь амплитуда сигнала.
* Таким образом бинауральный слух, играющий большую роль в локализации источника звука, лучше всего развит на частотах меньших 1.5кГц. Выше этой частоты источником информации о местоположении служит лишь разница амплитуд сигнала для левого и правого уха. Это делает возможным применение при кодировании режимов Joint Stereo - запоминается либо информация для суммы правого и левого каналов и их разница, со значительно меньшей точностью (Mid/Side coding), либо вообще запоминается лишь амплитуда сигнала (Intensity coding).
Психоакустика
Критические полосы (Critical Bands)
* Человеческая система восприятия звука имеет ограниченное, зависящее от частоты разрешение. Равномерное, с точки зрения восприятия человеком измерение частоты может быть выражено в единицах ширины Критических Полос.
Их ширина менее 100 Hz для нижних слышимых частот, и более 4 kHz для наиболее высоких. Весь частотный диапазон может быть разделен на 25 критических полос.
* Новый отсчет частоты был назван барк (bark, after Barkhausen):
1 Барк = ширина одной критической полосы
Для частот < 500 Hz, может быть рассчитан по формуле: частота / 100 Барк
Для частот > 500 Hz: 9 + 4log2(частота / 1000) Барк.
Чувствительность человеческого уха в зависимости от частоты
* Эксперимент: Слушатель в тихой комнате. Повышаем громкость тона частотой 1 kHz до уровня когда он становится слышимым. Изменяя частоту тона получим:

Частотное (параллельное) маскирование
Вопрос: Взаимодействуют ли звуковые рецепторы друг с другом ?
* Эксперимент: Воспроизводим тон частотой 1 kHz (маскирующий сигнал), с фиксированной громкостью (60 dB). Воспроизводим тестовый (маскируемый) тон с различной громкостью (скажем с частотой 1.1 kHz), и повышаем его уровень до тех пор пока он не становится слышимым.
* Изменяем частоту тестового тона и рисуем границу слышимости:

* Повторяем эксперимент для различных частот маскирующего сигнала:

* Частотное маскирование с частотной шкалой выраженной в Барках:

Временное (последовательное) маскирование
Если мы слышим громкий звук, который внезапно прекращается, требуется некоторое время чтобы услышать более тихий тон.
Эксперимент: Воспроизводим 1 kHz маскирующий тон на уровне 60 dB, и тестовый тон с частотой 1.1 kHz на уровне 40 dB. Тестовый тон не слышен (он замаскирован).
Отключаем маскирующий тон, затем, после небольшой задержки отключаем тестовый тон.
Уменьшаем время задержки до тех пор пока тестовый тон еще слышен (например 5 ms).
Повторяем используя различную громкость тестового тона и получаем:

Общий эффект от частотного и временного маскирования:

Транзиентные сигналы
Представленная выше теория маскирования верна в случае рассмотрения квазистационарных, медленно меняющихся по амплитуде и частотным характеристикам сигналов. В случае же рассмотрения сигналов с резко меняющимися параметрами (транзиентные сигналы) она неприменима.
Ухо в данном случае невозможно описать с помощью линейной системы. Теоретически обоснованных подходов для описания восприятия в данном случае автору не известно. Можно описать лишь несколько хорошо известных эффектов проявляющихся при кодировании данных сигналов:
* Пре-эхо (pre-echo, ringing). Возникает перед резкими увеличениями амплитуды сигнала (атаками). При кодировании с недостаточным временным разрешением (и выделением недостаточного количества бит при квантовании) часть сигнала предшествующая атаке существенно искажается шумом квантования. Так как существует эффект пре-маскирования, то некоторое искажение допустимо, однако оно должно быть достаточно коротким по времени. Некоторые исследования показывают, что время пре-маскирования уменьшается с увеличением частоты сигнала.
* Речевой сигнал. Голосовые участки речевого сигнала являются по своей природе часто идущими атаками с быстрым затуханием (pitched signals):

Стандартная психоакустическая модель маскирования сигналов в данном случае выдает завышенные пороги слышимости (из-за недостаточного временного разрешения) и, как результат, становится слышимым шум квантования.
____________________________
Audio Compression - с этой странички переведен раздел психоакустика.
Human audio perception: masking - более подробное описание эффектов маскирования.
GSM 6.10 описание и исходники GSM кодека.
Каталог ссылок на различные ресурсы по MPEG аудио.
SQAM Sound Quality Assesment Material - критический аудио-материал. Использовался при тестировании MPEG кодеров, при сжатии проявляется большее количество искажений, чем при использовании обычных записей.
Автор: Дмитрий Шмунк Взято [url=http://fdstar.com/2008/04/04/o_vospriyatii_zvuka_i_muzyki.html]ОТСЮДА[/url]
___________________________________
Статью подготовил и отредактировал [url=http://vk.com/necrodeflorator]NECRODEFLORATOR[/url], вся информация была взята из открытых источников в интернете. Специально для AmDm.ru
